No products in the cart.
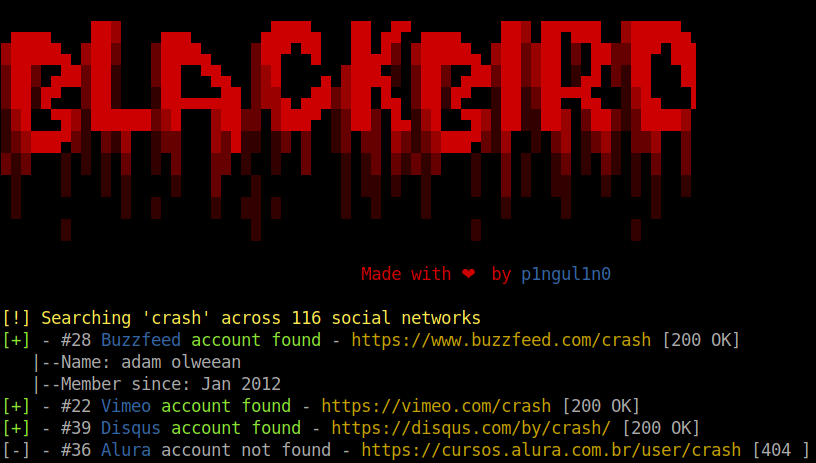
The Lockheed SR-71 "Blackbird" is a long-range, high-altitude, Mach 3+ strategic reconnaissance aircraft developed and manufactured by the American aerospace company Lockheed Corporation. https://github.com/p1ngul1n0/blackbird Disclaimer This or previous program is for educational purposes ONLY. Do not use it without permission. The usual disclaimer applies, especially the fact that me (P1ngul1n0) is not liable for any damages caused by direct or indirect use of the information or functionality provided by these programs. The author or any Internet provider bears NO responsibility for content or misuse of these programs or any derivatives thereof. By using these programs you accept the fact that any damage (dataloss, system crash, system compromise, etc.) caused by the use of these programs is not P1ngul1n0's responsibility. Setup Clone the repository git clone https://github.com/p1ngul1n0/blackbird cd blackbird Install requirements pip install -r requirements.txt Usage Search by username python blackbird.py -u username Run WebServer python blackbird.py --web Access https://127.0.0.1:5000 on....
A very big thanks to kelvinethicalhacker at gmail com for the great the work you done for me, i got the email address on the net web when i needed to hack my husband cell phone he helped me within few hours with whatsApp hacking and GPS location tracking direct from my person phone i know how my husband walks, thanks for the helped you do for me for every grateful for your helped, you can contact him through gmail via kelvinethicalhacker at gmail.com or Telegram, calls, text, number +1(341)465-4599, if you are in needed of hacking services, contact him..
A great hacker is really worthy of good recommendation , Henry
really help to get all the evidence i needed against my husband and
and i was able to confront him with this details from this great hacker
to get an amazing service done with the help ,he is good with what he does and the charges are affordable, I think all I owe him is publicity for a great work done via, Henryclarkethicalhacker at gmail com, and you can text, call him on whatsapp him on +12014305865, or +17736092741,
Well, I tried to edit my comment but it wouldn’t allow me.
I very very very stupidly forgot to type
python3Ignore my previous comment.
Does not seem to be compatible with python 3.10